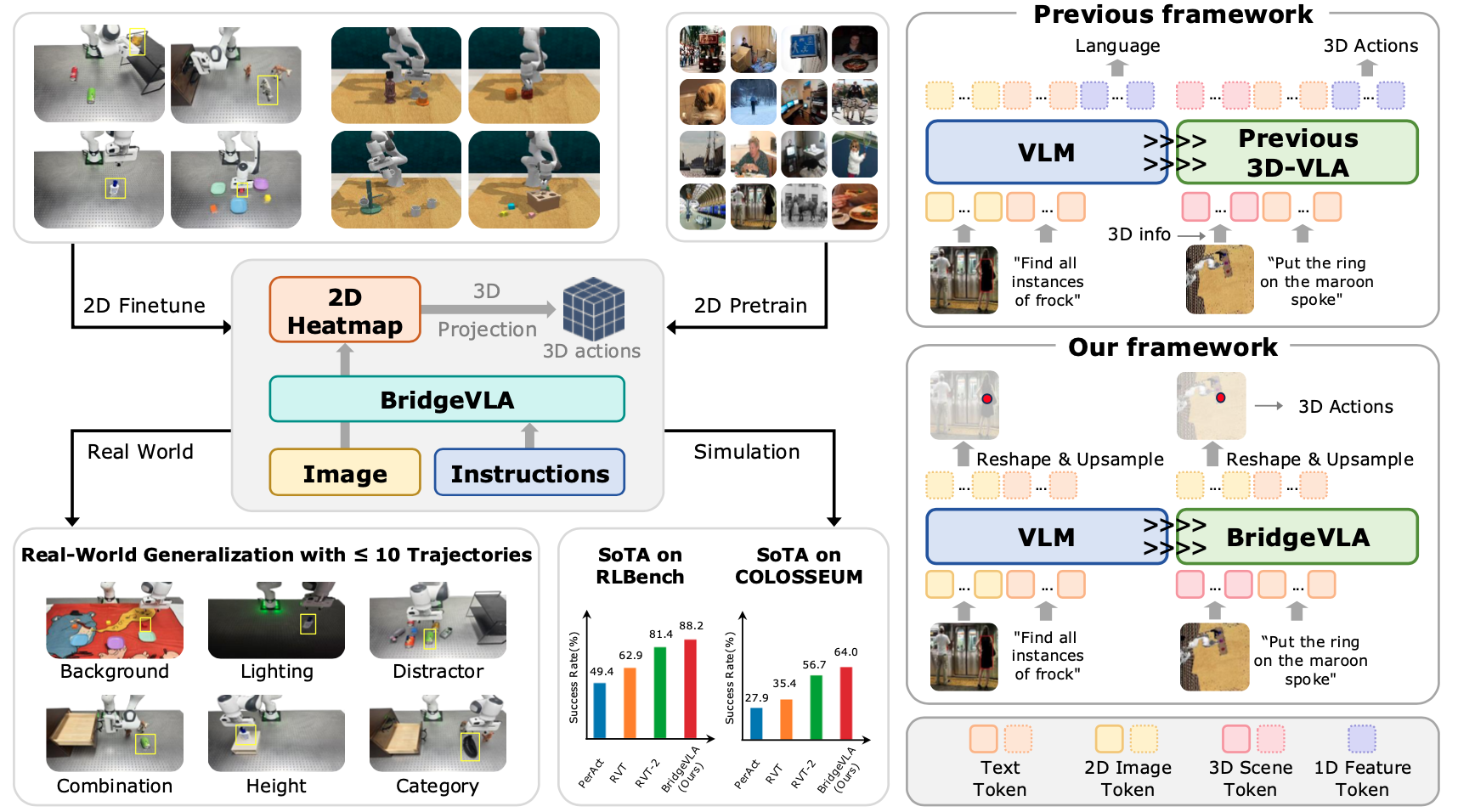
BridgeVLA
Input-Output Alignment for Efficient 3D Manipulation
Learning with Vision-Language Models
Please click to continue!