
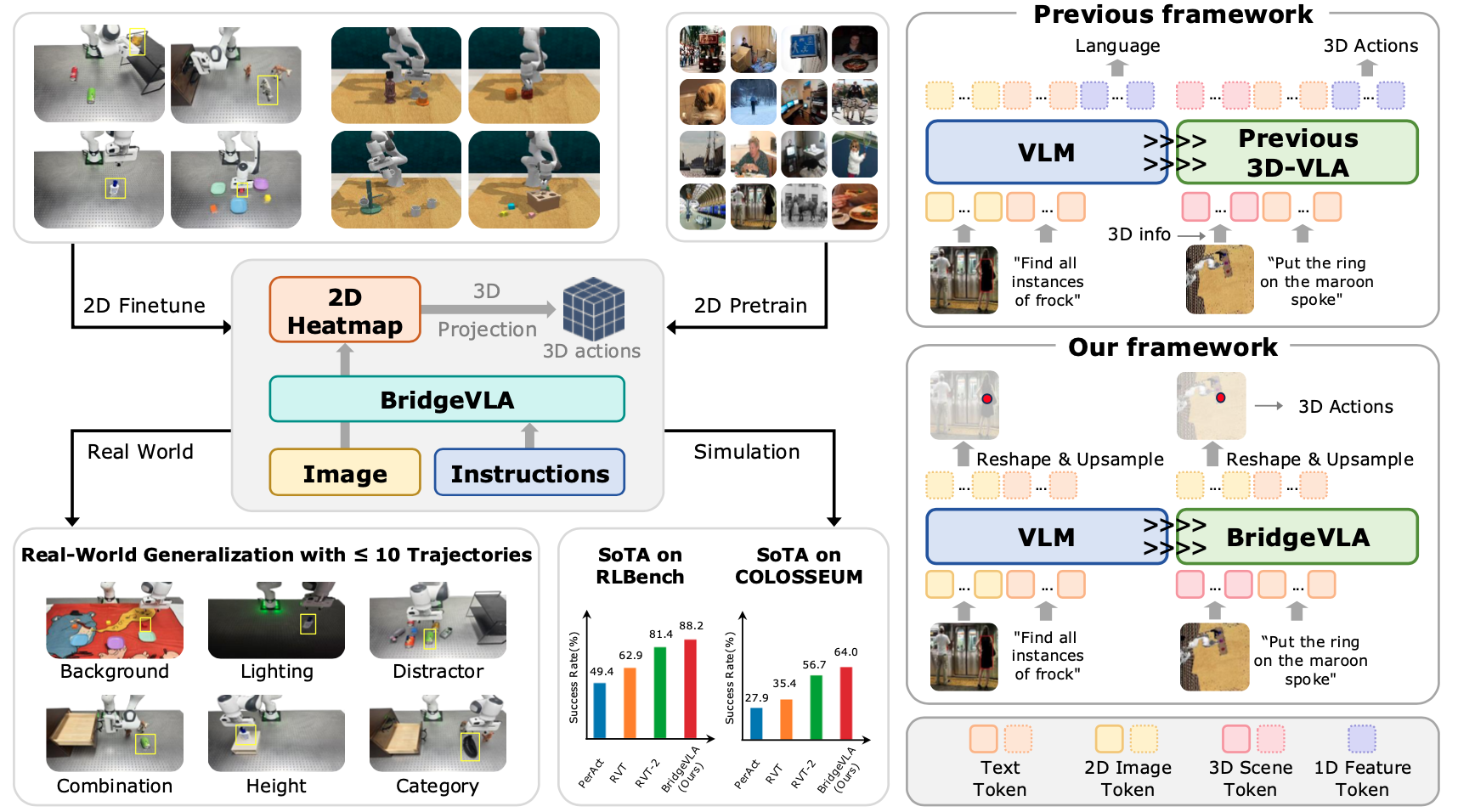
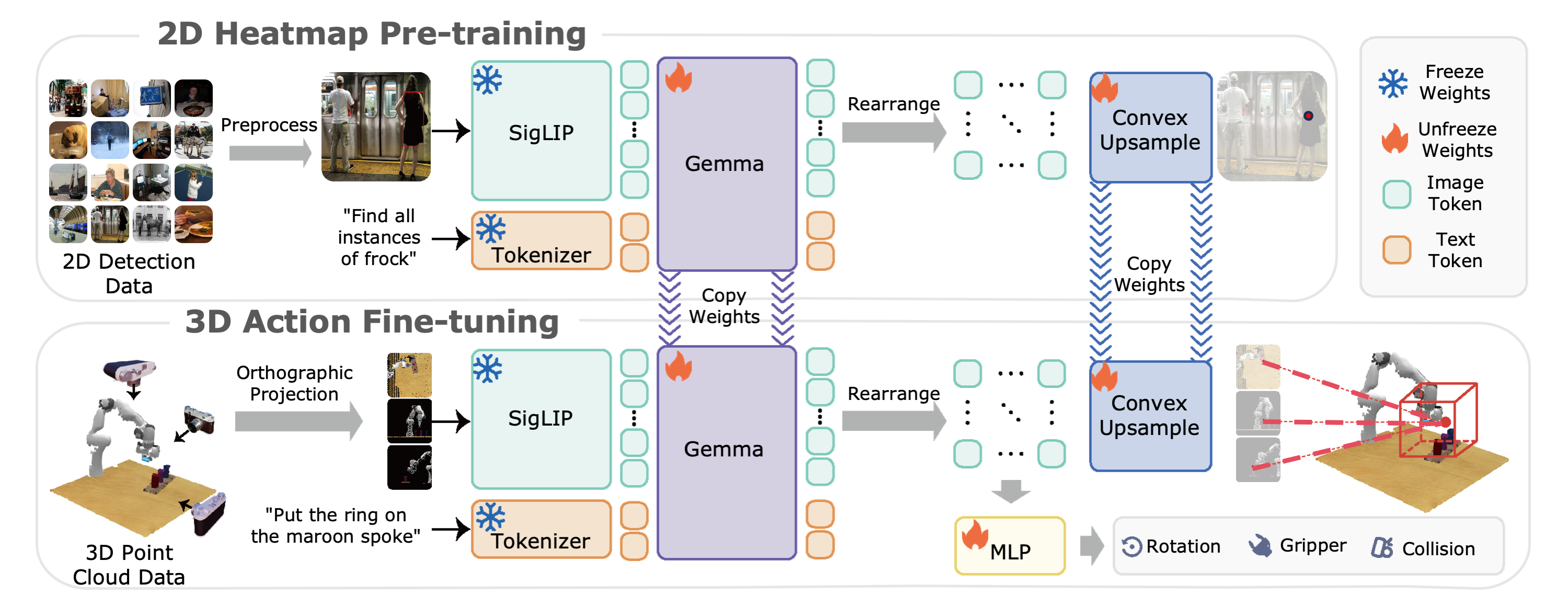
RLBench
To test our model's ability to deal with complex manipulation tasks, we evaluate BridgeVLA on RLBench, a benchmark implemented in CoppeliaSim using a Franka Panda robot mounted with a parallel-jaw gripper. Totally, we choose 18 tasks from RLBench, and each task is provided with 100 expert demonstrations. And each demonstration is paired with language instruction and multiple keyframes. Models are evaluated via binary success rates over 25 trials per task, with a maximum of 25 action steps per trial. The results are shown in Tab. 1.
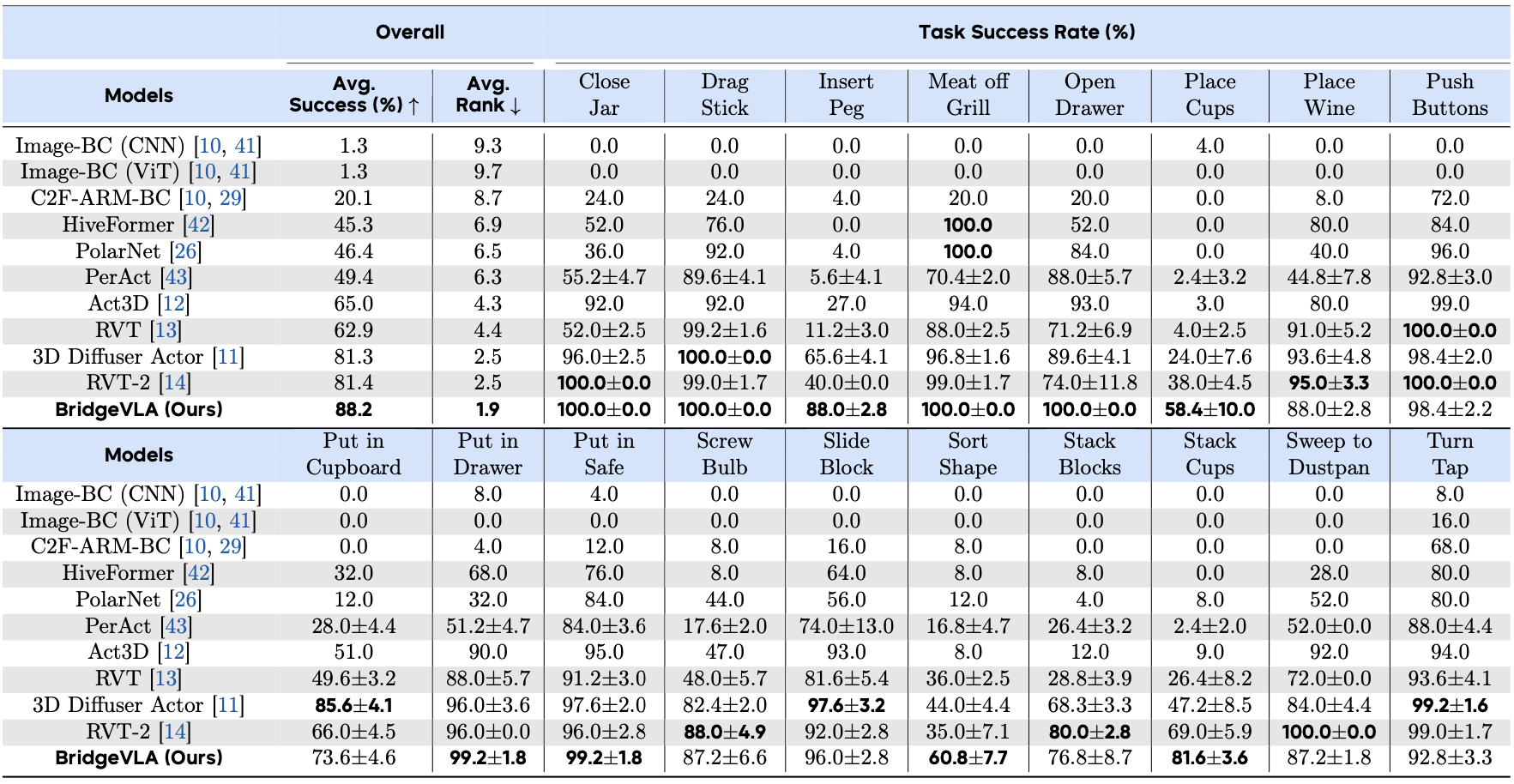
Table 1: Results on RLBench.
RLBench Task Demonstrations
Stack 4 Rose Blocks
Put Chocolate Jello in Cupboard
Place 3 Cups on Cup Holder
Close Blue Jar
Sweep Dirt to Dustpan
Screw in Lime Light Bulb
Put Money in Safe
Take Steak off Grill
Stack Cups on Navy Cup
COLOSSEUM
To systematically evaluate the generalization capabilities of BridgeVLA, we further evaluate on the COLOSSEUM benchmark. The COLOSSEUM benchmark is an extension to the RLBench benchmark. The model is trained on the data from the original RLBench benchmark but evaluated in environments spanning 12 axes of perturbations. These perturbations, which are unseen during training, encompass changes in object texture, color, and size, backgrounds, lighting, distractors and camera poses. Specifically, our evaluation includes three steps: 1) train the model with the original RLBench data without perturbations (100 trajectories per task) on 20 tasks, 2) evaluate each task over 25 trials per perturbation, 3) compute the average success rate of all evaluated tasks for every perturbation. Besides the 12 types of perturbations, we also evaluate on basic variations from the original RLBench (denoted as RLBench in Tab. 2), and a more challenging setting which combines all the 12 types of perturbations (denoted as All Perturbations in Tab. 2).
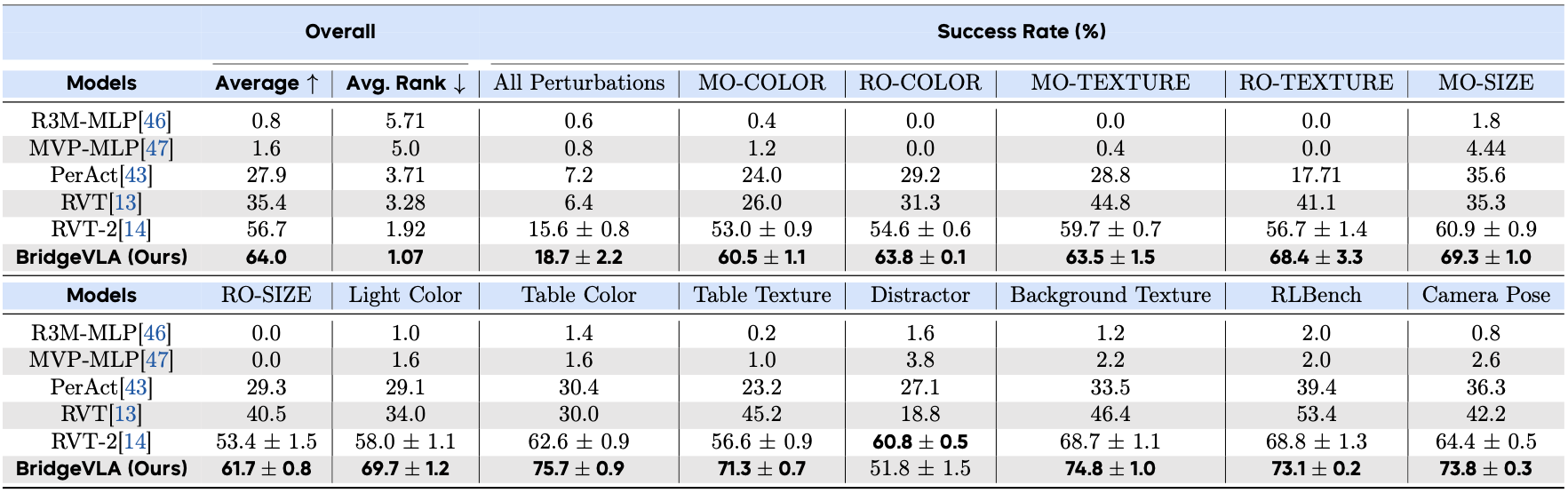
Table 2: Results on COLOSSEUM.
COLOSSEUM Task Demonstrations
Scoop with Spatula
Insert onto Square Peg
Close Laptop Lid
Move Hanger
Basketball in Hoop
Reach and Drag
Straighten Rope
Turn Oven On
Hockey Hit
GemBench
To more comprehensively assess the generalization ability of our proposed method, we evaluate BridgeVLA on GemBench, a comprehensive hierarchical benchmark built on the RLBench simulator. GemBench is designed to rigorously test 3D manipulation policies across a wide range of scenarios, covering 60 tasks and 123 variations organized into four progressively challenging levels—from simple novel placements to complex multi-step tasks involving novel object shapes and articulations. BridgeVLA demonstrates outstanding performance, achieving the highest average success rate across all evaluation levels. Notably, it sets new state-of-the-art results in both the L2 (novel rigid objects) and L3 (novel articulated objects) settings, where generalization to unseen object shapes and part combinations is particularly challenging. We show the results in Tab. 3.
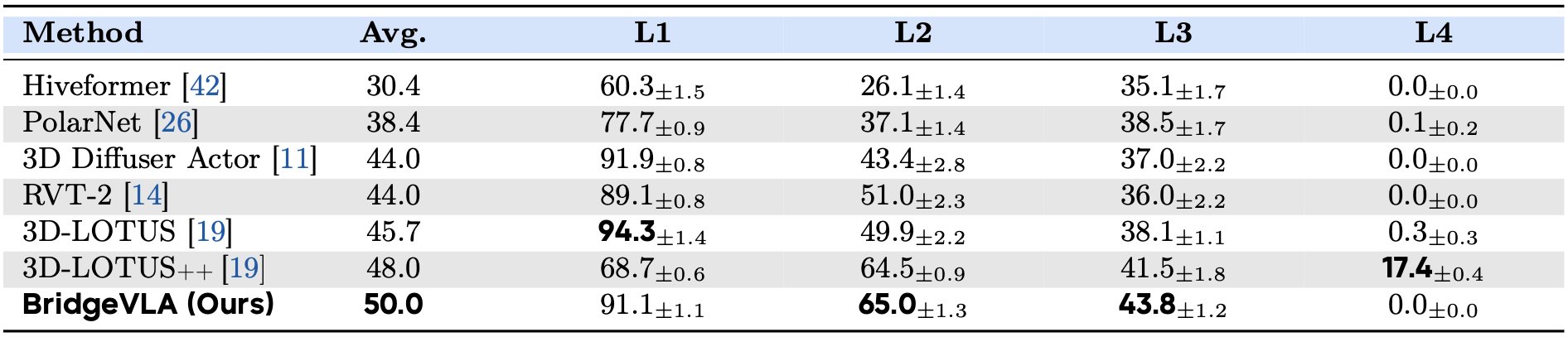
Table 3: Results on GemBench.
GemBench Task Demonstrations
Stack Blocks
Stack Cups
Put Money in Safe
Close Laptop Lid
Close Microwave
Close Grill
Push Button
Take Shoe Out of Box
Toilet Seat Up
Real-World Experiments
We conduct real-robot experiments to further verify our model's performance. A total of 13 manipulation tasks are evaluated, covering a spectrum from simple pick-and-place to long-horizon behaviors such as opening a drawer and placing objects inside.
Evaluation Settings
To systematically evaluate the robustness and generalization of BridgeVLA, we design seven distinct settings:
Basic: Tasks are evaluated under the same environmental conditions as training. This setting serves as a sanity check to ensure the model performs well under familiar conditions.
Distractor: Visually similar but irrelevant objects are added to the workspace. These distractors share shape or color characteristics with target objects, testing the model's ability to distinguish targets amid ambiguity.
Lighting: The robot operates under significantly different illumination, such as turning off overhead lights, to test robustness to lighting changes that affect the appearance of the scene.
Background: The visual background is altered by changing tablecloths (three variants in total), assessing the model's invariance to background textures and colors.
Height: All manipulable objects are placed on a raised surface (a drawer 9.5 cm above the base level), requiring the model to adapt its control to new object elevations.
Combination: Novel combinations of known objects and skills are introduced. While both the objects (e.g., a red block and green plate) and the manipulation skill (e.g., place A in B) are present in the training data, the pairing is new (e.g., "place the red block in the green plate"), challenging the model to generalize to unseen instructions.
Category: The model is asked to manipulate entirely unseen object categories during training. Seven such objects are introduced to evaluate whether pretrained visual-linguistic knowledge enables effective zero-shot generalization.
Results
In addition to the full model, we compare against RVT-2, the strongest simulation baseline, and an ablated variant of BridgeVLA without our proposed 2D-heatmap pretraining. The results are shown in Fig. 4. BridgeVLA outperforms both baselines in six of the seven settings, and maintains high robustness under visual disturbances (Distractor, Background).
Furthermore, it achieves a 96.8% success rate in the Basic setting even with only 3 training trajectories per task, showing remarkable data efficiency. The results also validate the effectiveness of our 2D-heatmap pretraining in connecting language and vision for compositional task generalization.
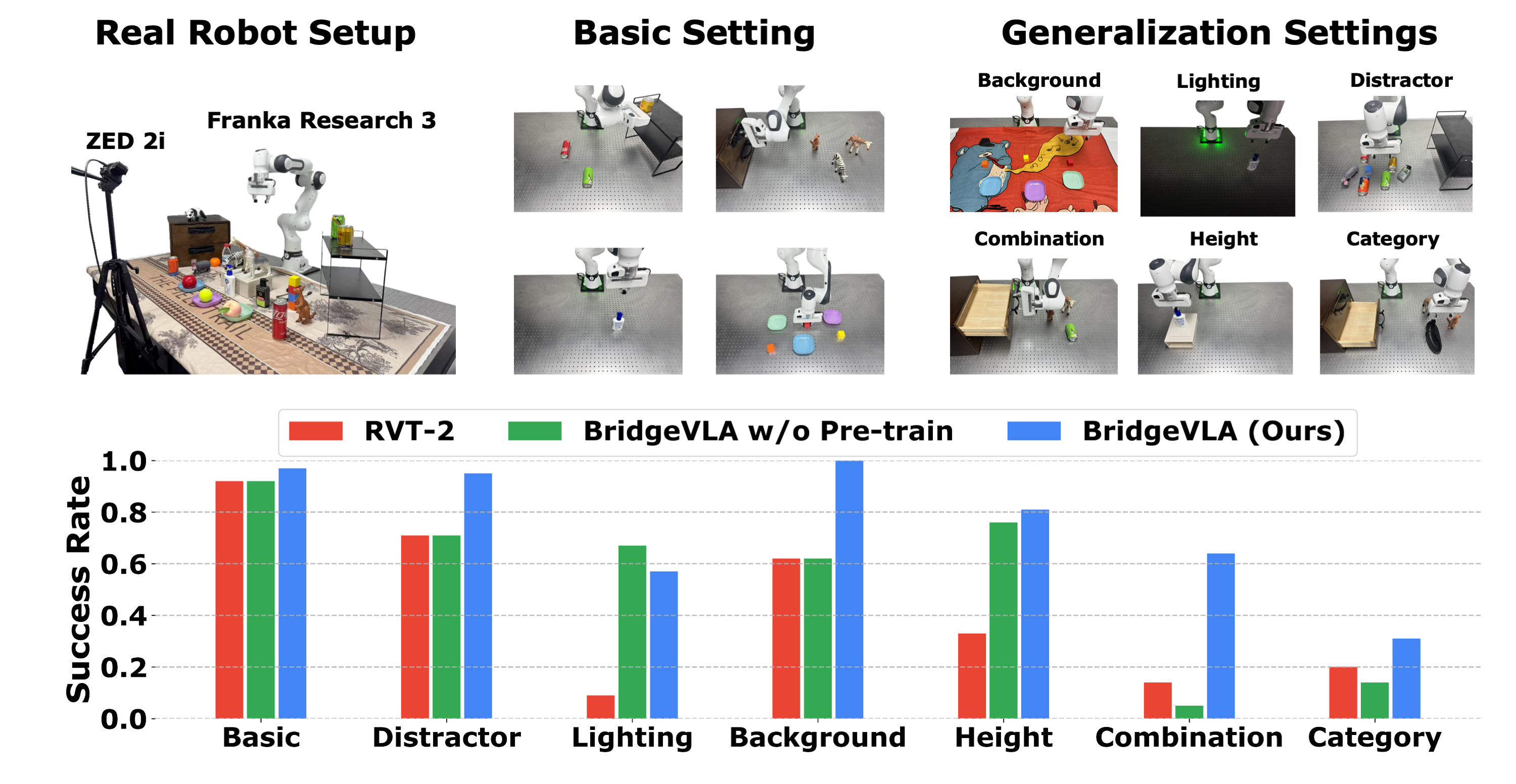
Figure 4: Real-robot setup and results.
Background
Place red block in blue plate
Put RedBull can on top shelf
Put zebra in upper drawer
Lighting
Put RedBull can on bottom shelf
Press sanitizer
Put giraffe in lower drawer
Distractor
Place orange block in green plate
Put giraffe in lower drawer
Press sanitizer
Combination
Put orange block in lower drawer
Put RedBull can in green plate
Place yellow block in purple plate
Height
Press sanitizer
Put soda can on bottom shelf
Place red block in blue plate
Category
Put peach on bottom shelf
Place bottle in blue plate
Put panda in lower drawer
Failure Cases
Although our method outperforms baseline methods in the Category setting, its absolute success rate is not high. We show some failure cases below.
Place bread in green plate
Put apple on top shelf
Put peach on bottom shelf
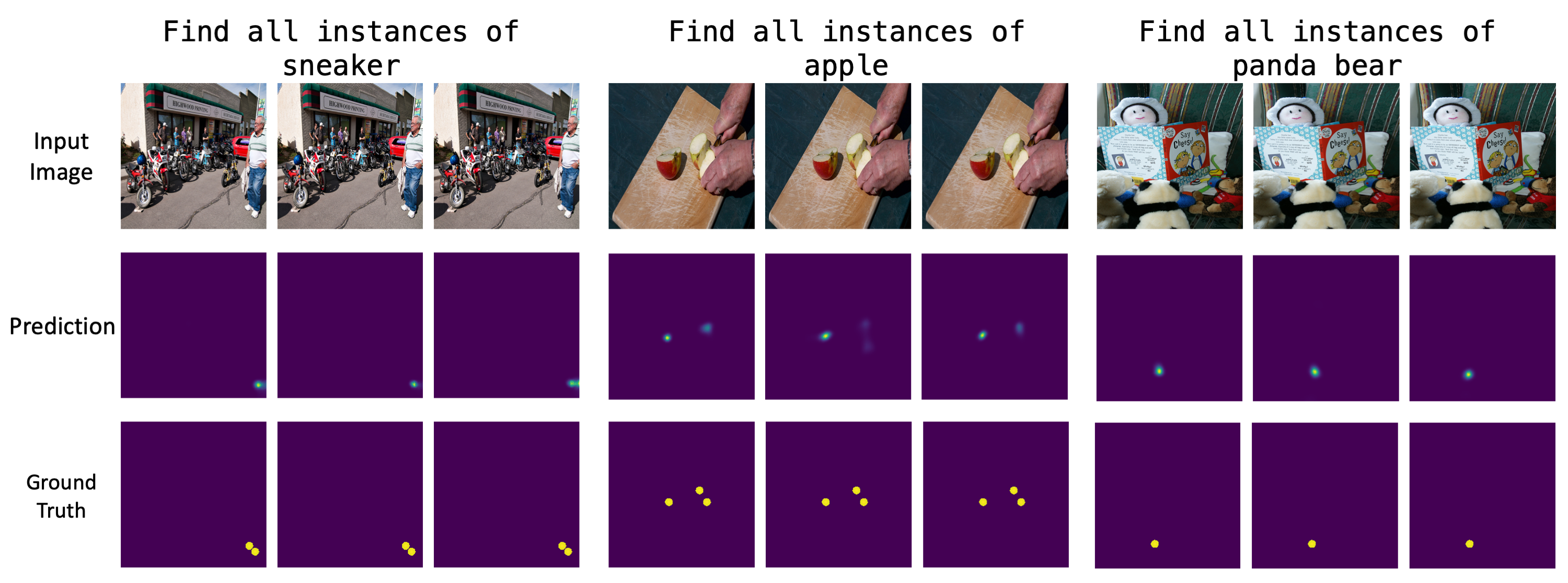
Figure 5: Prediction on pre-training data after fine-tuning.